Points of View 医療情報の更なる利活用に向けて 個人情報保護の観点から
医薬産業政策研究所 統括研究員 森田 正実
医薬産業政策研究所 主任研究員 佐々木隆之
医薬産業政策研究所 主任研究員 中塚 靖彦
日本政府は2019年6月21日に決定した「経済財政運営と改革の基本方針2019」(骨太方針)1)に「イノベーションの推進を図ること等により、製薬産業を高い創薬力を持つ産業構造に転換する」という一文を盛り込んだ。今回の骨太方針には、がんゲノムをはじめとしたデータやテクノロジーを活用した創薬支援の必要性が明記されている。副題には「『令和』新時代:『Society5.0』への挑戦」というメッセージが掲げられている。Society5.0の実現を目指す動きとしてカギとなるのがデータ流通である。
昨年2019年1月にスイス・ジュネーブで開催された世界経済フォーラム年次総会(ダボス会議)2)にて、安倍晋三首相がスピーチで「Data Free Flow with Trust(信頼性のある自由なデータ流通)」という言葉を提唱したことも記憶に新しいところである。また、首相は昨年6月に大阪で開催されたG20首脳会議の場でも「世界的なデータガバナンスが始まった機会として長く記憶される場としたい」と述べ、個人情報の安全性確保やデータ管理の高度化に向けた国際ルール作りを主導する考えを表明している。
実際、国際社会ではデータ技術の進歩とともにデータガバナンスのためのルール整備が進んでおり、そのルールには各極によって特徴がある。例えば、GAFAなどの巨大IT企業があるアメリカの場合は、個人データの自己管理を前提として、データを集積管理する企業などがプライバシーを配慮しつつ活用を進める対応が認められている。その一方、プライバシーや個人情報の取り扱いに厳正なヨーロッパでは「個人情報保護」の観点が重要視されており、「GDPR」によってより厳格なルール化が行われている。中国においては国家としてのデータ管理の重要性が強く打ち出され、中国政府は2017年に施行したサイバーセキュリティー法で、国家安全の目的から、国内で集めたデータの国外への持ち出しを制限し、国がデータを管理しデータを囲い込む政策をとっている。
わが国もデータ駆動型の産業競争力強化を実現するために、産業データ、個人データ利活用や情報保護等に関する制度、ガイドラインの見直し、データ共有を実施する事業者の認定制度等の整備を行っていく必要がある。2019年12月には個人情報保護法の制度改正大綱が発出され、遅れていた次世代医療基盤法の匿名加工事業者の認定が行われるなど、わが国においても個人情報保護の観点からデータを活用するためのルール整備等が進みつつある。そこで、本稿では個人情報保護法改正および次世代医療基盤法を中心に、今後、製薬産業が健康・医療データをさらに活用していくのに必要な課題は何か、考察したい。
個人情報保護法の改正等の動き
「個人情報保護に関する法律(以下、個人情報保護法)」は、直接的には住民基本台帳ネットワークシステムの導入に伴う住民基本台帳改正を受けて、2003年5月に公布、2005年4月に全面施行された。その後、情報通信技術の発展や事業活動のグローバル化等の急速な環境変化により、個人情報保護法が制定された当初は想定されなかったようなビッグデータの利活用が可能となるなど個人情報の取り扱いの広がりに大きな変化が出てきた。
そのような中、データ駆動活用に対する産業振興や個人の権利の保護を図るため2015年9月に改正個人情報保護法(2017年版)が公布され、2017年5月に全面施行となった。この際の議論において、国際的な動向も勘案しながら、個人情報保護法は3年ごとに見直しをすることになった。この3年ごとの見直しに対応すべく、昨年より次回改正の議論が本格化し、2019年12月13日に「個人情報保護法 いわゆる3年ごと見直し制度改正大綱」3)が発出された。2020年1月14日までパブリックコメントが募集されていたところである。この個人情報保護法改正大綱に記載されている製薬産業にとって関心の高い点を以下表1に記載する。

まずもっとも注目する点としては、第4節2項に、新たに「仮名化情報(仮称)」が記載されたことである。個人情報保護法では病歴等を含む個人情報が「要配慮個人情報」に位置付けられ、企業等が医療データを活用するためには個人の同意が必要であった。研究活用を進めるため次世代医療基盤法(後述)が制定され、医療機関における丁寧なオプトアウトでの収集と認定事業者による匿名加工により二次活用をすすめようとしているが、この「仮名化情報」という個人情報の取り扱いにより、将来的に二次活用を行う要件等が整備されていくことが期待される。
ここ数年、Cookie等の識別子に紐づく個人情報ではないユーザーデータを、提供先において他の情報と照合することにより個人データとなることをあらかじめ知りながら、他の事業者に提供する事業形態が出現している。このような本人関与のない個人情報の収集方法を規定すべく、第4節4項(3)では提供元基準を基本とし、個人データの第3者提供を制限する規律を取り入れることとした。このような規律によって、個人情報としての管理の下で適切に個人データが提供されることとなる。
また、第4節3項の「公益目的による個人情報の取り扱いに係る例外規定の運用の明確化」では、具体的事例として、「安全面や効果面で質の高い医療サービスや医薬品、医療機器等の実現に向け、医療機関や製薬会社が、医学研究の発展に資する目的で利用する場合」が取り上げられた。いわゆる公益性の概念が広がり、民間企業の活動の一部も公益性のある活動として捉えられれば、2次活用において民間企業のデータへのアクセシビリティが向上することが期待できる。例示にもあるように、医学研究の発展に資する医薬品等の創出を目的とした民間企業によるデータの利用といった公益性の高い活動について、ガイドライン等による明確化を進めてほしい。
また、第6節3項の「外国にある第三者への個人データの提供制限の強化」では、同意を取る際に、域外移転時の移転先の明示が求められることとなる。一般的に医薬品等の研究開発においては、臨床試験により日本で取得したデータを海外の事業者や審査当局等に提供(移転)するケースが存在する。しかしながら、臨床試験に参加してもらう際の被験者への同意取得を行う時点では、承認申請する国は未確定であり、個人データの提供(移転)先についての詳細な説明は困難である。この海外へのデータ移転時の対応については、取り扱う事業者の負担や実務に十分配慮され、過度な負担とならないような検討を期待したい。
第7節2項、3項には、個人情報の保護に関する規程を集約・一体化することが記載された。予てより指摘のあるところであるが、行政機関、地方公共団体など規程や所管が異なることにより日本の個人情報保護法制はおよそ2,000個にも及ぶ法律と条令群によって構成されているといわれている(個人情報保護法2,000個問題)。例えば、2015年改正で新たに導入された「個人識別符号」という用語・概念を採用している条例が極めて少ないため、個人識別符号に該当するゲノム情報、生体識別システム等で生成された特徴量情報単体が各自治体では「個人情報」に該当しないところも出てくるなど、国内で統一がとれていない状況となっている。また、上述の第4節3項における「学術研究目的の適用除外」規定をもたない個人情報保護条例が多数存在し、公立研究機関、公立大学、及び公立病院等の学術研究利用にそれぞれの自治体の条例の適用が課されることになり、自治体ごとの個人情報保護審査会の承認を得る必要があるなど学術研究等の発展の妨げになっているのが現状である。今後、製薬産業においては医療分野から生活分野まで分野を横断してビッグデータ解析が効果的に行われることが期待されるため、個人情報の取り扱いが各自治体でバラバラなことによってデータ利活用が妨げられないよう、土台となるルールを統一することが必要であろう。
次世代医療基盤法による取り組み
国内における医療データの活用を考える上で、期待される取り組みの一つが、「医療分野の研究開発に資するための匿名加工医療情報に関する法律(以下、次世代医療基盤法)」5)に基づくインフラ整備である。2017年5月に施行された改正個人情報保護法によって、病歴等を含む個人情報が「要配慮個人情報」に位置付けられ、オプトアウトによる第三者提供が禁止されたことにより、医学研究等における医療情報の活用に支障が出るのではないかと懸念された。予てより診療行為のアウトカムを含んだ電子カルテを中心とした全国規模のデータベース構築の重要性も認識され、その構築に向けた取り組みについての議論もあった6)。
こうした背景のもと、医療分野の研究開発を推進するために2018年5月に施行されたのが、次世代医療基盤法である。この法律によって、高いセキュリティや匿名加工技術などの一定の基準を満たす事業者(認定匿名加工医療情報作成事業者(以下、認定事業者))を認定する仕組み7)が定められ、さらにこの認定された事業者に対しては、医療機関等がオプトアウトで要配慮個人情報を含む医療情報を提供でき、匿名加工したうえで、その情報を医療分野の研究開発に提供できることが定められた(図1)。
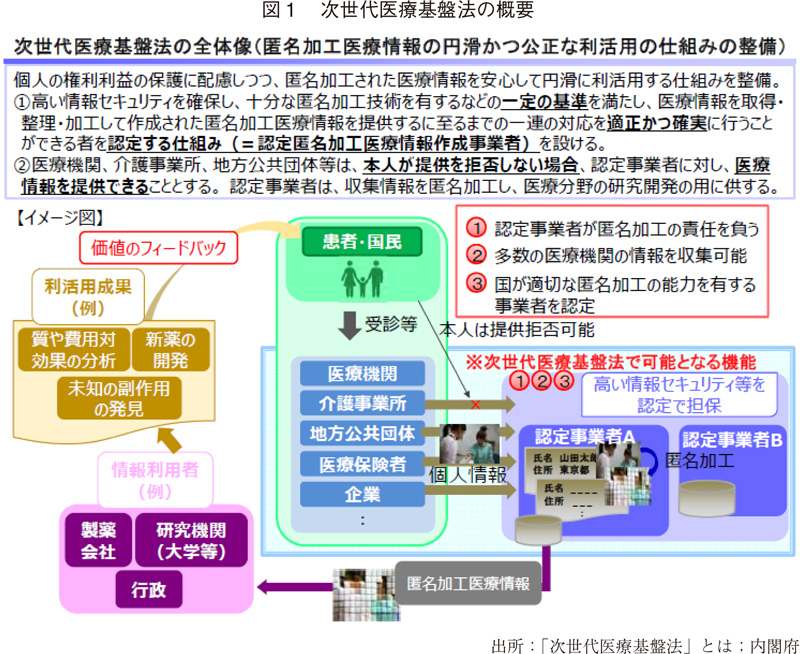
2019年12月には次世代医療基盤法の認定事業者が認定され、2020年1月より本基盤法における認定事業者の活動が開始している。この認定事業者の第1号は、一般社団法人ライフデータイニシアティブであり、本事業者は京都大学を中心とした千年カルテプロジェクト8)を基盤とした事業者である。ライフデータイニシアティブ社は「健康・医療全般の情報の利活用者、参加施設へのサービス展開により、日本の医療発展に寄与できる事業を行うと共に医療の質・効率性や患者・国民の利便性向上、臨床研究等の研究開発、産業競争力の強化、持続可能な利用システム実現へ貢献すること」を事業の目的としている9)。
医療施設ネットワークの拡大や、電子カルテ情報の集積、集積データのクレンジングなどを進めているが、当初は「市場調査代行」ならびにデータベース研究による論文作成を支援する「学術支援」サービスを開始時には予定しており、体制が整い次第「製造販売後調査支援」、「匿名加工情報提供」10)などのサービス提供を本格化する予定である。製薬企業等の民間企業が利用者となるが、現時点では実際にどのような項目、粒度のデータが利活用可能になるのか等不透明な部分もある。当初の準備期間を通じて、データの内容やニーズなどを共有化するなど、利活用する民間事業者との連携を深める必要があるだろう。
今後、上述の認定事業者のサービスにより医療情報の利活用が進んでいくことが期待されるが、この次世代医療基盤法の仕組みにはいくつか課題も感じる。
まず一点目として、特異性が高く個人を特定しうる記載内容(希少疾患、超高齢者の情報等を含む)や画像データ(脳のスキャンデータ、レントゲン、臓器写真等)等の匿名化の取り扱いについてである。このような情報では個人の特定を防ぐため、記述や画像を削除、もしくは丸め処理をするといった匿名化の処理が考えられ、提供データとしてオリジナルの情報が得られない恐れがある。特に、今後の希少疾患に対する研究開発や医療の層別化の進展、画像解析AIなど先進技術の活用を見越した場合、「狭くても深いデータ」の価値はますます増大していくと考えられ、特異性の高い医療情報の二次利用の活用(可能性)についてさらに議論していく必要があるだろう。
二点目として、ゲノム(オミックス)データの情報提供についてである。一般にゲノム情報は個人識別符号に該当するため、匿名加工そのものができない。つまり、個人情報そのものであり、個人の同意を得なければ、次世代医療基盤法のスキームの中では活用することができないこととなる。今後の医学研究、創薬研究においては、ゲノム(オミックス)データと医療データ、及び日々の生活データ等とを連結し、疾患の発症、悪化のメカニズムや予後の予測、あらたなバイオマーカーの発掘等へとつなげることは重要なテーマであり、ゲノム(オミックス)データの提供ができる仕組みについて更なる検討が必要であろう。
三点目には、認定事業者が取り扱うデータは数百施設から収集された一般の診療情報(電子カルテ情報等)のため、データの正確性や測定項目の欠落、検査値の単位や各コードの不整合等が存在することが考えられることである。この点は次世代医療基盤法の問題というよりは、電子カルテ、EHRの標準化や構造化といったそもそものデータの質の問題であるが、匿名加工医療情報の利活用範囲が製造販売後や市場調査など特定の領域に限られてしまうことが懸念される。次世代医療基盤法の運用スキームの中で、レジストリーのように、疾患によっては収集データのフォーマットを事前に決めてテンプレートのようなものを用いデータ収集を行うなど、データの質を高める工夫も必要かもしれない。
最後に、製造販売後や市場調査の領域では、既に市販データベースを活用しデータベース活用事業を行っているメディカル・データ・ビジョンやJMDCなどの民間企業もあり、データの質や量、及び認定事業者のデータ利用料も含め、既存事業者との差別化を図っていくことも期待される。
「仮名化情報」利活用のための体制整備
また、今回の個人情報保護法改正によって設定される「仮名化情報」を医療分野で収集・分析できるように体制を整備していくことも製薬産業にとっては重要な検討テーマである。
個人情報保護法改正大綱で示された「仮名化情報(仮称)」は、匿名加工情報等の非個人情報と異なり、「個人情報」であって、第三者に提供するためには依然として本人の同意が必要となる。ただし、仮名化情報は一見で個人が識別されないように氏名、住所、カルテ番号等を削除した情報であり、一定の義務の下で一人ひとりの正確な履歴データをそのまま2次活用でも使えることが期待される情報である。したがって、次世代医療基盤法が、個人情報保護法(一般法)に対する医療分野での特別法として制定されたように、仮名化情報を取り扱えるような新たな法の制定も一つの方策であろう。
もちろん、仮名化情報は個人情報であり、適切な利用目的の範囲内で利活用できるようにする前提であることは言うまでもない。この「適切な利用目的」は、個人情報保護法改正に伴って提示されるガイドラインやQ&A等の細目通知なども考慮しながら明確化していくことが期待されるが、仮名化情報を取扱いできる「対象をどうするか」と「どのような利用」に限定するかといった検討がポイントとなるだろう。すなわち、仮名化を担うデータ取扱い主体である「対象」をあらかじめ指定された資格者(例えば医師や指定された研究者など)に制限し、社会性、公益性の高い「利用目的」に限定するなど種々の法定の制限の下に、「仮名化情報」という個人情報提供のルール化を検討するといった慎重なスタンスが必要となる。
例えば、利用目的としては公益性を軸に、①学術研究目的・公衆衛生目的(適用除外条項の整備)と②データ提供者への分析データ還元(治療、予防につながるデータ提供)が認められるべきである。次に、社会的なコンセンサスの形成を図りながら、③民間企業の創薬目的、次いで、④健康ソリューション開発目的などの類型を示したうえで、一定の公益性評価軸に沿った活用を検討するなどが考えられる。
新たなデータガバナンス概念の提唱
ヘルスケア領域のデータ利活用についてさらに掘り下げた考え方として、世界経済フォーラム(WEF:World Economic Forum)からAuthorized Public Purpose Access(APPA)という新たなデータガバナンスの概念が報告された11)。本報告では、適切なデータガバナンスモデルの具体的な構成要素を示し、不適切なデータ利用を避けると同時に、データ利活用のあるべき姿の例としてAPPAが提示されている。
APPAは、個人の人権を尊重する方法として、必ずしも「個人の」オプトインでの同意だけに拠らない新たなガバナンスモデルであり、医学医療の発展や公衆衛生の向上等の、合意がなされた特定の公的な目的のためであれば、必ずしも明示的な個人同意によることなく個人の人権を別の形で保障し、データへのアクセスを許可することで目的とする価値を実現するモデルである。
本報告では、利活用におけるガバナンスモデルの要素として、個人、データホルダー、公益の3要素が整理されており、APPAはそれぞれが過剰に偏る問題ケース(個人偏重、データホルダーの利益偏重、公益偏重)への対応法のひとつとして位置づけられている。
また、利用するデータや個人への影響に応じ、然るべきプロセスを踏む必要があるとし、個人同意に代わって、合意や第三者機関の活用も一つの手段として挙げられているが、今後、3要素の扱いに関する議論に基づき、より具体的な方法を示すことでAPPAモデルの信頼性が高まるものと考えられている。一方、経済的に持続可能なモデルとして構築されること、効率的な同意の取得、プライバシーリスクを最小化するテクノロジーの活用などの諸課題も挙げられており、今後更なる議論が望まれるところである。
まとめ
今回は、健康・医療情報の利活用促進の観点から、個人情報保護法の改正、次世代医療基盤法の課題、APPAの概念について触れた。健康・医療情報は通常機微情報であり、プライバシーが保護されていることを前提としてデータ活用を進める必要があるが、データ提供者の一面からのみこれを捉えるのでなく、利活用の目的の側面(公益性)からも議論が始まっていることは注目すべき点であろう。別の言い方をすれば、データポータビリティがありさえすればよいわけではなく、そのデータが誰にどう使われ、どう閲覧され、どうフィードバックされるかという「トラスト」もまた、データエコシステムの重要な要素であると言えよう。
ただし、これらの要素は法律のみで規定できるものではなく、社会の仕組みとして実装することが最も重要である。米欧中をはじめ世界中でデータ利活用の体制が整備されつつある。わが国においても、同意取得の効率化、経済的に持続可能なモデルの構築やプライバシーリスクを最小化するテクノロジーの活用といった諸要素を組み合わせた『社会のデザイン』が必要であり、様々なステークホルダーを交え、早期に議論を開始する必要があるだろう。
-
※医薬産業政策研究所ではビッグデータの製薬産業に関する課題を研究するために、所内に『医療健康分野のビッグデータ活用・研究会』を2015年7月発足させた。今回の報告は、新潟大学 鈴木 正朝先生の講演など、『研究会』の調査研究に基づいてまとめたものである。
-
1)
-
2)
「世界経済フォーラム年次総会」、外務省
-
3)
-
4)仮名化情報:氏名等特定の個人を直接識別できる記述を、他の記述に置換・削除し、加工後のデータ単体からは特定個人を識別できないよう加工したもの。個人データに該当する。
-
5)
-
6)医薬産業政策研究所、「医療健康分野のビッグデータ活用研究会報告書 Vol.3」、(2018年5月)
-
7)
-
8)医薬産業政策研究所、「医療健康分野のビッグデータ活用研究会 報告書Vol.2」、(2017年4月)
-
9)
-
10)匿名加工医療情報:特定の個人を識別することができないように個人情報を加工して得られる個人に関する情報であって、もとの個人情報を復元できないようにしたもの。例えば、紙面に関する項目の全てを削除したり、年齢の表記を全て年代の表記に一般化して置き換えたり、特定の個人の情報を示す項目などを削除するなどの措置をしたもの。個人データに該当しない。
-
11)
APPA:Building Trust into Data Flows for Well-being and Innovation ホワイトペーパー(2020年1月17日)、World Economic Forum